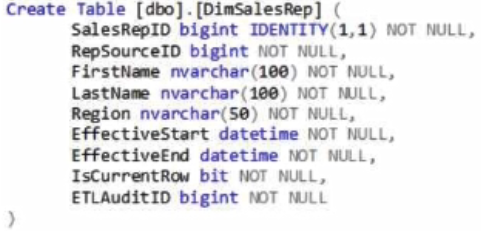
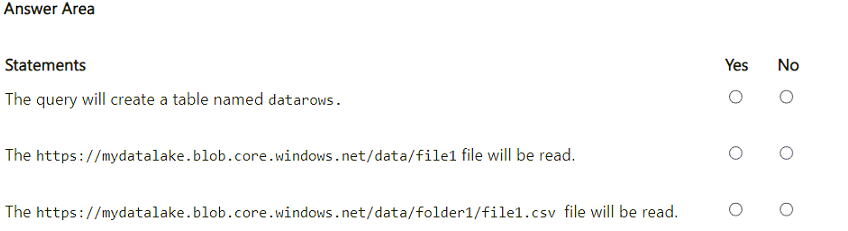
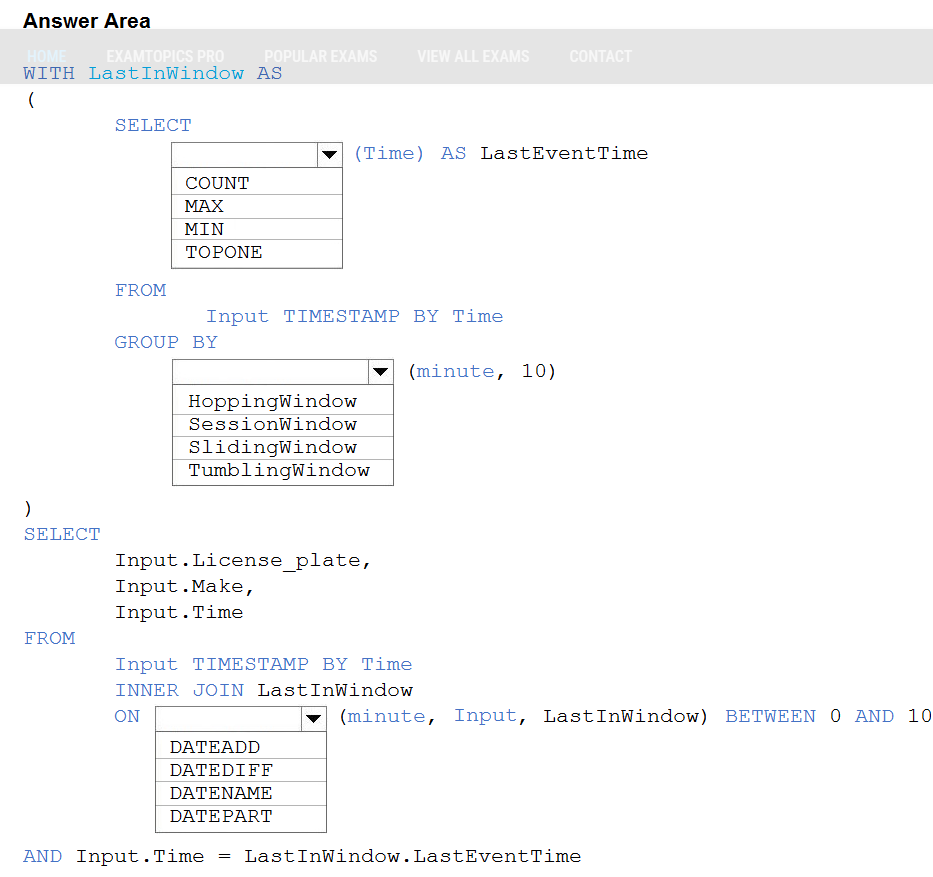
Question 91
Open question ↗You are developing a solution that will stream to Azure Stream Analytics. The solution will have both streaming data and reference data.
Which input type should you use for the reference data?
- A.Azure Service Bus
- B.Azure Blob storage
- C.Azure IoT Hub
- D.Azure Event Hubs