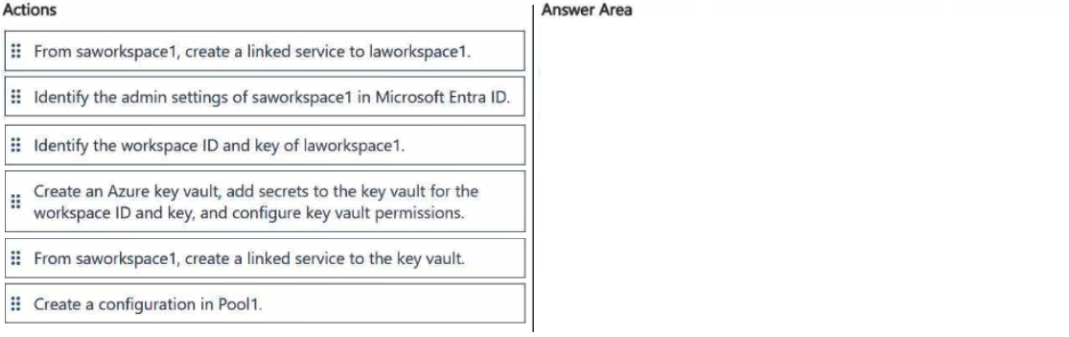
Question 281
Open question ↗You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1.
You need to monitor Pool1. The solution must ensure that you capture the start and end times of each query completed in Pool1.
Which diagnostic setting should you use?
- A.Sql Requests
- B.Request Steps
- C.Dms Workers
- D.Exec Requests