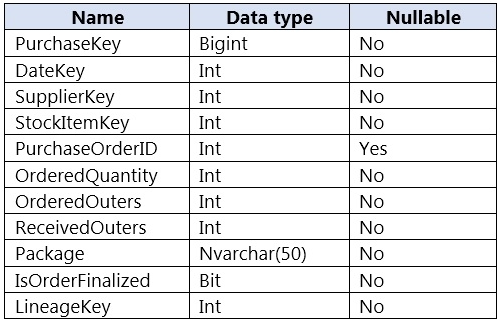
Question 31
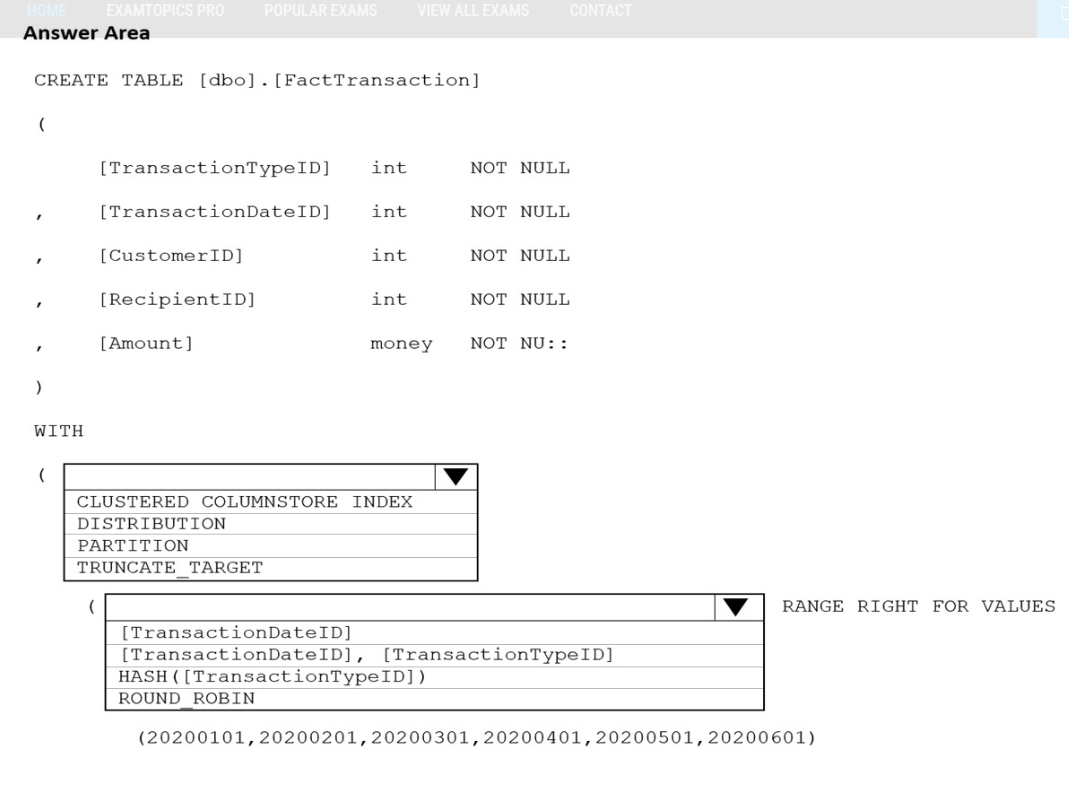
Open question ↗You are designing a partition strategy for a fact table in an Azure Synapse Analytics dedicated SQL pool. The table has the following specifications:
✑ Contain sales data for 20,000 products.
Use hash distribution on a column named ProductID.
✑ Contain 2.4 billion records for the years 2019 and 2020.
Which number of partition ranges provides optimal compression and performance for the clustered columnstore index?
- A.40
- B.240
- C.400
- D.2,400