Question 61
Open question ↗You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool.
You plan to deploy a solution that will analyze sales data and include the following:
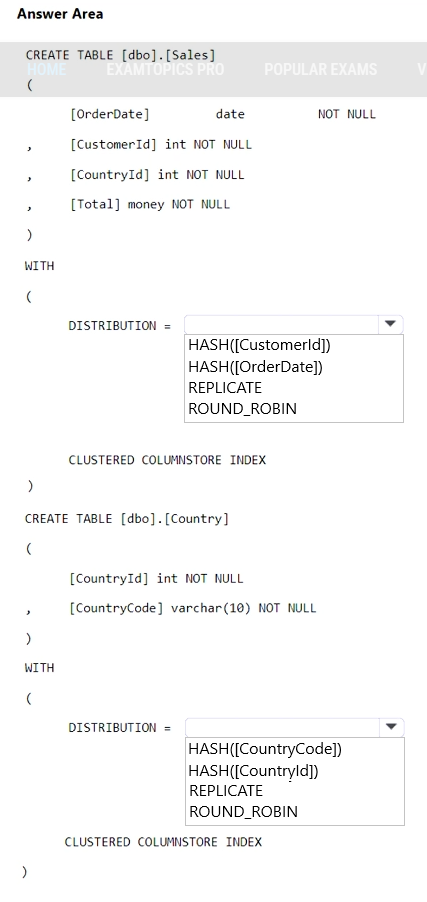
• A table named Country that will contain 195 rows
• A table named Sales that will contain 100 million rows
• A query to identify total sales by country and customer from the past 30 days
You need to create the tables. The solution must maximize query performance.
How should you complete the script? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.