Question 71
Open question ↗You are incrementally loading data into fact tables in an Azure Synapse Analytics dedicated SQL pool.
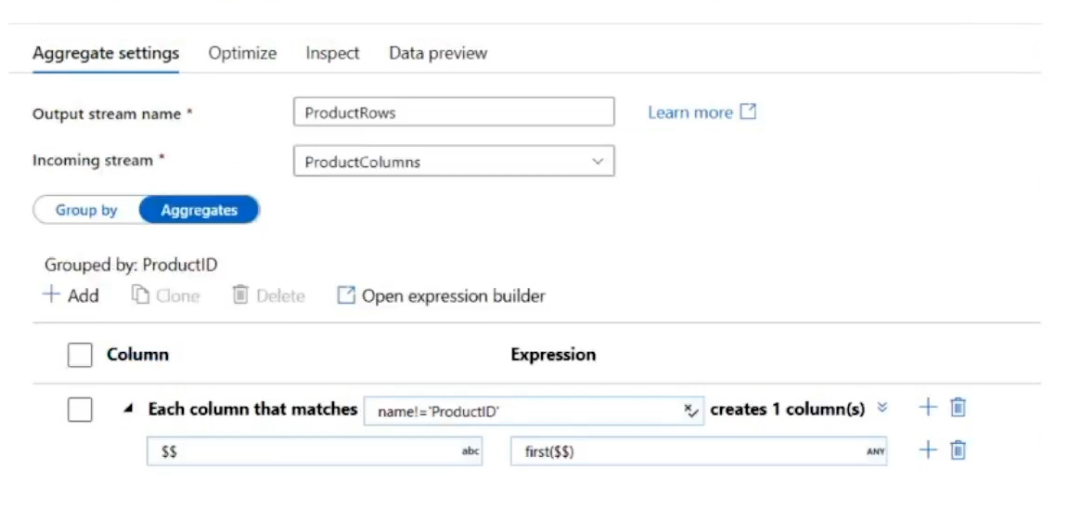
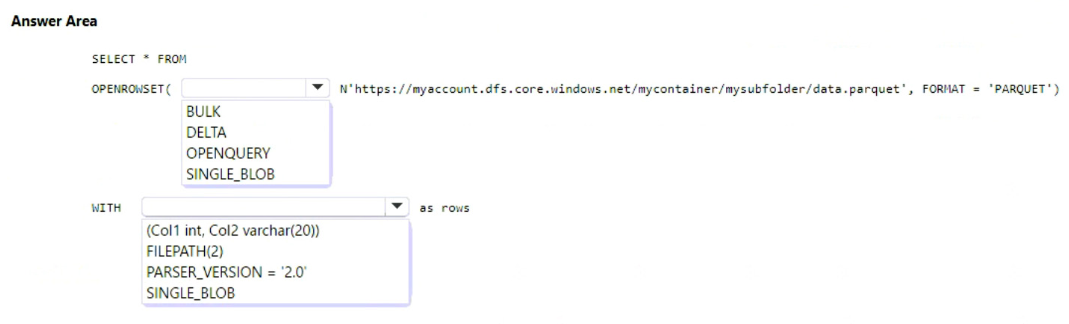
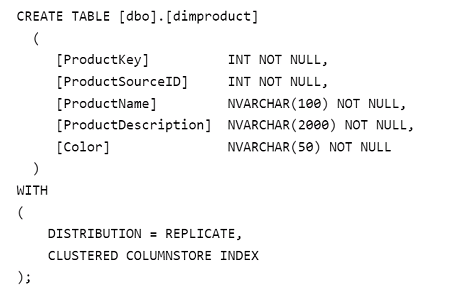
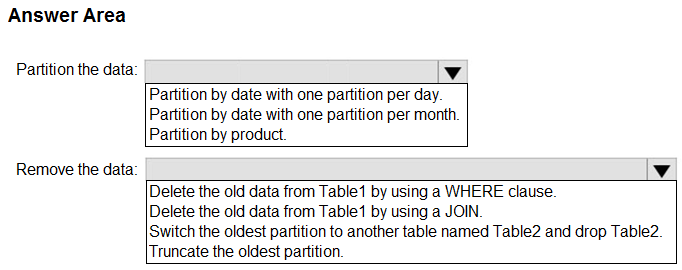
Each batch of incoming data is staged before being loaded into the fact tables.
You need to ensure that the incoming data is staged as quickly as possible.
How should you configure the staging tables? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.